So, as previously discussed there is a second way to find elements using TestComplete...by their TestObject properties.
To start, open up Internet Explorer, navigate back to http://www.google.com/, and click on the object browser tab in TestComplete. Expand iexplore, and then click on the Page("http://www.google.com/") node. On the right half of the page, click on the Methods tab, and take a second to scroll through the list. These are the methods that TC found as available in the iexplore process, on the page node. You will see a total of five find functions, all of which are usable interchangeably. Most of these are usable interchangeably, the main distinction between them is where they start looking from, and whether they return one or multiple results. Here they are, along with their parameters:
Find(propertyName, propertyValue, depth, refresh)
FindAll(propertyName, propertyValue, depth, refresh)
FindAllChildren(propertyName, propertyValue, depth, refresh)
FindChild(propertyName, propertyValue, depth, refresh)
FindId(id, refresh)
Here is a quick explanation of the differences between the five Find functions. First, Find, FindChild, and FindId all return a single TestObject. FindAll and FindAllChildren return an array of TestObjects. The only other difference is that FindChild and FindAllChildren do NOT check the current node, they start at the first child node.
Depth is how deep in the tree TC should look, and refresh determines if TestComplete needs to refresh its cache of the Page again (necessary if something has changed).
The last thing to know is that propertyName and propertyValue can be variants OR arrays. this is great, because you can find an element based upon several criteria, to make sure you have the correct one. However, due to some inherent issues with the way javascript and TestComplete works, you have to convert the arrays to a VBScript array first. However, that over-complicates things, so I'm going to ignore them for the time being.
The only other thing to note is that FindId searches for the TestObject unique id. This is the fastest and most efficient Find method, but there is no way of knowing the Id of an element before hand, since they are generated at run-time, they will always be different. You could, however, get the Id of an TestObject you are already at, and use the FindId function to reference it later. But there are other ways to do this same thing. (such as assigning the TestObject to a variant). I personally don't use the FindId function at all.
So, for our purposes of web-based testing, we really only need two find functions, Find() and FindAll(). Using the object finder, highlight the google search box, and view it in the object browser. Now, scroll through the properties, and start thinking about which of these you can use to find this later. It needs to be something unique, and something that won't ever change.
We have several options:
Name = Textbox("q")
Title = Google Search
ObjectType = Textbox
className = lst
Any or all of these could possibly be used to find our textbox. Lets try some and see how they work. Copy and paste the following into TC:
function Find()
{
var searchBox = Page().Find("Title","Google Search",100);
var searchButton = Page().Find("type","submit",100);
searchBox.value="TC Find still rocks";
searchButton.Click();
}
Go ahead and run this script. It finds the textbox correctly, and modifies the text, however, it clicks the "I feel lucky" button, and not the google search button. Why? It turns out, both buttons have type = submit. So TC returned the first node that matched our criteria, which was not the correct one. Why didn't this happen in our last example using NativeWebObject.Find? It turns out that the TestObject.Find function parses the tree in reverse order, so it will always return the last element on the page, whereas NativeWebObject.Find goes from top to bottom.
There are a couple ways we could fix this. We could use FindAll, and get an array if we want to have access to both buttons. We could then do whatever we wanted, like returning the last element, or Of course, the easiest way to fix this is to get better search criteria.
So, ask yourself, how does a person know which one to click on? Well, in this case the text on the buttons is different, so lets try a Find based upon that.
function Find()
{
var searchBox = Page().Find("Title","Google Search",100);
var searchButton = Page().Find("value","Google Search",100);
searchBox.value="TC Find still rocks";
searchButton.Click();
}
Now, when we run our function, we click the correct button. So this works great...except that if we try to run this function a second time, on the Google Results page, it doesn't work!!! Why not? Well, the button text on the Google results page says "Search", whereas on the Google search page it says "Google Search". So TC can't find it. So what do we do now? Well, there are once again several options. We can add a wildcard "*" to the string, but that doesn't really work either. I think its easier to just change our search and search for name. (as I discussed earlier we could also pass an array of Names and Values, and search for multiple criteria)
function Find()
{
var searchBox = Page().Find("Name","Textbox*q*",100);
var searchButton = Page().Find("Name","SubmitButton*btnG*",100);
searchBox.value="TC Find still rocks";
searchButton.Click();
}
So now we have, once again, a function that works for both the google search page, and the google results page. We could easily functionize this with some parameters, and call it with whatever we want.
But you can see, its much harder and more complicated to use the TestObject.Find functionality, instead of the NativeWebObject.Find functionality, but we have much greater control over what we are searching for. However, for any modern web page, NativeWebObject.Find will work for 90% of the elements. Any decent programming shop should be using some sort of unique identifier for their web page elements, whether it be id, name or class. But, at least we know how to use the other if we have no other option.
Tuesday, October 20, 2009
Monday, October 19, 2009
finding what you need
So I thought next I would go over the various ways to find the elements that we are looking for on a web page, or windows process. We have already seen how to locate an element by it's path, and if you remember there are several drawbacks to that approach. The most obvious is that if the path changes, our tests will break. One solution is to use the object-mapping feature of TestComplete, which essentially stores all the elements' paths separately from our scripts. However, you have to update them every time your paths change, and this tends to be cumbersome and time consuming. The obvious solution to this problem is to not locate elements by their path, but rather find them based upon some criteria. There are two main ways to find elements: by their html elements, or by their TestComplete elements.
To illustrate, go to http://www.google.com/ again, and use the highlighter tool to select the google search box, and view it in the object browser. You will see something like this:
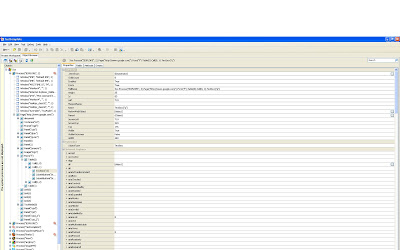
So the list of elements in the "properties" tab displays the properties of the given element we have selected. Now these are technically the properties of the "Test Object" class. Everything that TC knows about the node is displayed here. Take a second to look through the list of properties. Note the fields "name" and "id". The id is a unique number that TC uses to identify every Test object. The Name field (Textbox("q")) is a generated string that TC creates based upon the html fields. These are NOT the same as the id and name in the html document. If you scroll down to the "outerHTML" field, you will see the actual HTML associated with the element:
INPUT class=lst title="Google Search" maxLength=2048 size=55 name=q autocomplete="off" init="true"
Note that it also has a "Name" equal to "q". Compare this to the Name field, which is Textbox("q"). Obviously in this case the name field is generated based upon the type of element, combined with its html name. It is important to understand the distinction between the HTML elements and the TestObject elements: they are not interchangeable, however in many cases either can be used.
Ok, now that we understand that important distinction, we can look at the first of our Find functions, specific to HTML:
Copy and paste the following into TC:
function searchWithGoogle()
{
var searchBox = Page().NativeWebObject.Find("name","q","INPUT");
var searchButton = Page().NativeWebObject.Find("type","submit","INPUT");
searchBox.value="TestComplete Find Rocks!";
searchButton.Click();
}
The NativeWebObject class is what gives us access to the actual HTML elements, and not the Test Object properties. The NativeWebObject.Find() routine is defined like this:
Page().NativeWebObject.Find(propertyName, propertyValue, TagName)
Looking in the outerHTML field showed me what to search for. So, for the first Find call, I searched for the "INPUT" tag with property "name" with value "q". For the second, i searched for the INPUT tag with type=submit. Right-click on the function and Run it!. It will find the google search box and modify the value and then click the search button. The cool part? Remember in my first post, how the search results page had a different layout and structure than the search page? Our tests wouldn't run from the results page because the paths were slightly different. Well, if you run the routine again, you will see that it works perfectly the second and third times as well.
I want to point out that you can use this find functionality for anything contained in the "outerHTML" field for any element on a web page. You can search for a link with specific text, or look for a picture with a certain size, or even find a input field of a specific class. However, the big catch is that it returns the first element to match the criteria, so be aware that there could be multiple results that match your criteria.
At this point, it would be simple to modify our function to have a "search string" paramater, and we would then have a functionized google search routine, that can search for anything we want. We could even add more code to verify that we are on the correct page, and that we have search results. At this point we are only a couple steps away from creating a complete automated validation of a search page.
Since this post has gotten a little long winded, my next one will focus on finding an element based upon its TestObject properties, and not HTML elements. There will be definite times when the object you are trying to access doesn't have enough unique identifiers to find it consistently by html alone.
To illustrate, go to http://www.google.com/ again, and use the highlighter tool to select the google search box, and view it in the object browser. You will see something like this:

So the list of elements in the "properties" tab displays the properties of the given element we have selected. Now these are technically the properties of the "Test Object" class. Everything that TC knows about the node is displayed here. Take a second to look through the list of properties. Note the fields "name" and "id". The id is a unique number that TC uses to identify every Test object. The Name field (Textbox("q")) is a generated string that TC creates based upon the html fields. These are NOT the same as the id and name in the html document. If you scroll down to the "outerHTML" field, you will see the actual HTML associated with the element:
INPUT class=lst title="Google Search" maxLength=2048 size=55 name=q autocomplete="off" init="true"
Note that it also has a "Name" equal to "q". Compare this to the Name field, which is Textbox("q"). Obviously in this case the name field is generated based upon the type of element, combined with its html name. It is important to understand the distinction between the HTML elements and the TestObject elements: they are not interchangeable, however in many cases either can be used.
Ok, now that we understand that important distinction, we can look at the first of our Find functions, specific to HTML:
Copy and paste the following into TC:
function searchWithGoogle()
{
var searchBox = Page().NativeWebObject.Find("name","q","INPUT");
var searchButton = Page().NativeWebObject.Find("type","submit","INPUT");
searchBox.value="TestComplete Find Rocks!";
searchButton.Click();
}
The NativeWebObject class is what gives us access to the actual HTML elements, and not the Test Object properties. The NativeWebObject.Find() routine is defined like this:
Page().NativeWebObject.Find(propertyName, propertyValue, TagName)
Looking in the outerHTML field showed me what to search for. So, for the first Find call, I searched for the "INPUT" tag with property "name" with value "q". For the second, i searched for the INPUT tag with type=submit. Right-click on the function and Run it!. It will find the google search box and modify the value and then click the search button. The cool part? Remember in my first post, how the search results page had a different layout and structure than the search page? Our tests wouldn't run from the results page because the paths were slightly different. Well, if you run the routine again, you will see that it works perfectly the second and third times as well.
I want to point out that you can use this find functionality for anything contained in the "outerHTML" field for any element on a web page. You can search for a link with specific text, or look for a picture with a certain size, or even find a input field of a specific class. However, the big catch is that it returns the first element to match the criteria, so be aware that there could be multiple results that match your criteria.
At this point, it would be simple to modify our function to have a "search string" paramater, and we would then have a functionized google search routine, that can search for anything we want. We could even add more code to verify that we are on the correct page, and that we have search results. At this point we are only a couple steps away from creating a complete automated validation of a search page.
Since this post has gotten a little long winded, my next one will focus on finding an element based upon its TestObject properties, and not HTML elements. There will be definite times when the object you are trying to access doesn't have enough unique identifiers to find it consistently by html alone.
Tuesday, September 22, 2009
functionizing the Page object
So, for my next post, I thought I would focus on the first step to web-testing with TC. A simple function to return the page object of your browser. Using a function for this allows you to code for both IE and FF simultaneously, in addition to allowing you to use more complex logic to look through multiple windows, check for navigation warnings, or anything else you need.
To start, open up TC7, and IE7. Navigate to any web page, for this example we can use google. Go to google and search for testcomplete. (this is important so we are on the search results page). The url should be : http://www.google.com/search?hl=en&source=hp&q=testcomplete&aq=f&oq=&aqi=g1g-s1g4g-s1g1g-s2. If your url is different, modify any references to the url to match YOUR url.
Now using the object finder, highlight the search box, and look at its path:
Sys.Process("iexplore").Page("http://www.google.com/search?hl=en&source=hp&q=testcomplete&aq=f&oq=&aqi=g1g-s1g4g-s1g1g-s2").Panel("header").Form("tsf").Table("sft").Cell(0, 1).Table(0).Cell(0, 0).Textbox("q")
Textbox("q") is the search field we are trying to access. If you look at its properties, you will see a "value" field. Anything entered into the text field will be stored as its value, and by modifying this directly we can interact with the search box.
Now that we have a unique identifier for the search textbox on the page, and we know how to modify it. We can use this to access our object, and perform searches, but if anything about the path changes (such as the url) our test will break.
To illustrate, put the following function into your Project (using javascript as your language). There are two lines, the first line modifies the search parameter, the second step clicks on the search button.
function testGoogle()
{
Sys.Process("iexplore").Page("http://www.google.com/search?hl=en&source=hp&q=testcomplete&aq=f&oq=&aqi=g1g-s1g4g-s1g1g-s2").Panel("header").Form("tsf").Table("sft").Cell(0, 1).Table(0).Cell(0, 0).Textbox("q").value="TestComplete Tricks";
Sys.Process("iexplore").Page("http://www.google.com/search?hl=en&source=hp&q=testcomplete&aq=f&oq=&aqi=g1g-s1g4g-s1g1g-s2").Panel("header").Form("tsf").Table("sft").Cell(0, 1).Table(0).Cell(0, 0).SubmitButton("btnG").Click();
}
Right click inside the function, and Run the Current Routine. TC should modify the search box to be the words "TextComplete Tricks", and then click the search button. Congrats, you have just automated a google search.
Now, if you try to run the function a second time, it will fail. Why? Because our url changed. There are a couple options on what to do now. The easiest is to use wildcards to remove the url from inside Page(), and replace it with Page("*"). This tells TC to use ANY open page, which works fine as long as we only have 1 window or tab open. If you have more than one, it will pick one essentially randomly. And if it picks the wrong one, your tests will fail in a giant flame. We can also have a substring, so you can modify it to say Page("*google*"), and this will use the page that contains google in the url.
Again, this works, but we will need to modify every single instance of the Page() call every time we change url's. Or, if we want to run the same test in firefox, we will need a completely different test.
The easy solution is to create a new function called Page(). We can then create custom logic to determine which page object we want to use.
So, copy and paste the following function into TC.
function Page()
{
return Sys.Process("iexplore").Page("*");
}
This function returns the Page object of ANY open IE page. We can then modify our original function to be as follows, and the run the routine. You can execute this multiple times, or change the search string, and it will not fail.
function testGoogle()
{
Page().Panel("header").Form("tsf").Table("sft").Cell(0, 1).Table(0).Cell(0, 0).Textbox("q").value="TestComplete Tricks";
Page().Panel("header").Form("tsf").Table("sft").Cell(0, 1).Table(0).Cell(0, 0).SubmitButton("btnG").Click();
}
In addition, note how much smaller and more compact our code is. In addition, if we want to put a if/else statement in to switch between FF and IE (with say a global variable), our tests will now work for both browsers. In addition, if we want to add Opera/Chrome support at a later date, we just need to add another if/else statement to the Page() function, and not modify our tests at all.
As an example I have modified our Page() function to have a switch for a simple variable. We would typically use this as a global variable, but for this demonstration I have included it in the Page() function.
function Page()
{
var Browser = "IE";
if(Browser=="IE")
{
return Sys.Process("iexplore").Page("*");
}
if(Browser=="FF")
{
return Sys.Process("firefox").Page("*");
}
}
Now all we need to do is modify the Browser variant, and our tests will run in both IE and FF.
However, there is still a problem. To illustrate, navigate to http://www.google.com/ and execute our TestGoogle() function. It will fail. Why? Because the path of the search box is different on the google home page than it is on a google search results page.
Here is the path to the search box on the home page:
Page().Form("f").Table(0).Cell(0, 1).Textbox("q")
And here is the path to the search box on the search results page:
Page().Panel("header").Form("tsf").Table("sft").Cell(0, 1).Table(0).Cell(0, 0).Textbox("q").value="TestComplete Tricks";
The search box/button is located in a different spot on the search results page, and cannot be accessed using the same path. However, we don't really care about the path. All we need is to get to that Textbox("q") node and SubmitButton("btnG") node, which is what we need to modify to perform our search.
Finally, here is the Page() function I use in my own testing. This was not designed to switch between IE and FF, but was designed to restart IE if it locks up, freezes, or is not open.
function Page()
{
var page = Sys.Process("iexplore").WaitPage("*",10000);
if(!page.exists)
{
while(Sys.WaitProcess("iexplore",1000).Exists)
{
Sys.Process("iexplore").Terminate();
}
Open_Browser();
}
return page;
}
My next post will focus on how to use find functionality to find the elements you are looking for, instead of locating them by path.
To start, open up TC7, and IE7. Navigate to any web page, for this example we can use google. Go to google and search for testcomplete. (this is important so we are on the search results page). The url should be : http://www.google.com/search?hl=en&source=hp&q=testcomplete&aq=f&oq=&aqi=g1g-s1g4g-s1g1g-s2. If your url is different, modify any references to the url to match YOUR url.
Now using the object finder, highlight the search box, and look at its path:
Sys.Process("iexplore").Page("http://www.google.com/search?hl=en&source=hp&q=testcomplete&aq=f&oq=&aqi=g1g-s1g4g-s1g1g-s2").Panel("header").Form("tsf").Table("sft").Cell(0, 1).Table(0).Cell(0, 0).Textbox("q")
Textbox("q") is the search field we are trying to access. If you look at its properties, you will see a "value" field. Anything entered into the text field will be stored as its value, and by modifying this directly we can interact with the search box.
Now that we have a unique identifier for the search textbox on the page, and we know how to modify it. We can use this to access our object, and perform searches, but if anything about the path changes (such as the url) our test will break.
To illustrate, put the following function into your Project (using javascript as your language). There are two lines, the first line modifies the search parameter, the second step clicks on the search button.
function testGoogle()
{
Sys.Process("iexplore").Page("http://www.google.com/search?hl=en&source=hp&q=testcomplete&aq=f&oq=&aqi=g1g-s1g4g-s1g1g-s2").Panel("header").Form("tsf").Table("sft").Cell(0, 1).Table(0).Cell(0, 0).Textbox("q").value="TestComplete Tricks";
Sys.Process("iexplore").Page("http://www.google.com/search?hl=en&source=hp&q=testcomplete&aq=f&oq=&aqi=g1g-s1g4g-s1g1g-s2").Panel("header").Form("tsf").Table("sft").Cell(0, 1).Table(0).Cell(0, 0).SubmitButton("btnG").Click();
}
Right click inside the function, and Run the Current Routine. TC should modify the search box to be the words "TextComplete Tricks", and then click the search button. Congrats, you have just automated a google search.
Now, if you try to run the function a second time, it will fail. Why? Because our url changed. There are a couple options on what to do now. The easiest is to use wildcards to remove the url from inside Page(), and replace it with Page("*"). This tells TC to use ANY open page, which works fine as long as we only have 1 window or tab open. If you have more than one, it will pick one essentially randomly. And if it picks the wrong one, your tests will fail in a giant flame. We can also have a substring, so you can modify it to say Page("*google*"), and this will use the page that contains google in the url.
Again, this works, but we will need to modify every single instance of the Page() call every time we change url's. Or, if we want to run the same test in firefox, we will need a completely different test.
The easy solution is to create a new function called Page(). We can then create custom logic to determine which page object we want to use.
So, copy and paste the following function into TC.
function Page()
{
return Sys.Process("iexplore").Page("*");
}
This function returns the Page object of ANY open IE page. We can then modify our original function to be as follows, and the run the routine. You can execute this multiple times, or change the search string, and it will not fail.
function testGoogle()
{
Page().Panel("header").Form("tsf").Table("sft").Cell(0, 1).Table(0).Cell(0, 0).Textbox("q").value="TestComplete Tricks";
Page().Panel("header").Form("tsf").Table("sft").Cell(0, 1).Table(0).Cell(0, 0).SubmitButton("btnG").Click();
}
In addition, note how much smaller and more compact our code is. In addition, if we want to put a if/else statement in to switch between FF and IE (with say a global variable), our tests will now work for both browsers. In addition, if we want to add Opera/Chrome support at a later date, we just need to add another if/else statement to the Page() function, and not modify our tests at all.
As an example I have modified our Page() function to have a switch for a simple variable. We would typically use this as a global variable, but for this demonstration I have included it in the Page() function.
function Page()
{
var Browser = "IE";
if(Browser=="IE")
{
return Sys.Process("iexplore").Page("*");
}
if(Browser=="FF")
{
return Sys.Process("firefox").Page("*");
}
}
Now all we need to do is modify the Browser variant, and our tests will run in both IE and FF.
However, there is still a problem. To illustrate, navigate to http://www.google.com/ and execute our TestGoogle() function. It will fail. Why? Because the path of the search box is different on the google home page than it is on a google search results page.
Here is the path to the search box on the home page:
Page().Form("f").Table(0).Cell(0, 1).Textbox("q")
And here is the path to the search box on the search results page:
Page().Panel("header").Form("tsf").Table("sft").Cell(0, 1).Table(0).Cell(0, 0).Textbox("q").value="TestComplete Tricks";
The search box/button is located in a different spot on the search results page, and cannot be accessed using the same path. However, we don't really care about the path. All we need is to get to that Textbox("q") node and SubmitButton("btnG") node, which is what we need to modify to perform our search.
Finally, here is the Page() function I use in my own testing. This was not designed to switch between IE and FF, but was designed to restart IE if it locks up, freezes, or is not open.
function Page()
{
var page = Sys.Process("iexplore").WaitPage("*",10000);
if(!page.exists)
{
while(Sys.WaitProcess("iexplore",1000).Exists)
{
Sys.Process("iexplore").Terminate();
}
Open_Browser();
}
return page;
}
My next post will focus on how to use find functionality to find the elements you are looking for, instead of locating them by path.
Monday, September 21, 2009
The Object Browser Is Your Friend
For my first post, I thought I would cover the most important functional tool of TestComplete for anyone who hasn't worked with it before. The awe-inspiring, all-powerful, all-knowing "Object Browser" .
First, open up TC7, and click on the "Object Browser" tab, in the upper left hand corner of TC. On the left, you will see a list of the currently running processes. On the right, a list of elements associated with the currently selected node. These elements include attributes, methods, events, and fields associated with the node.

By default all processes are shown, minus windows processes. If you want, you can choose to only display tested applications, or display windows processes as well. The object browser lets you see inside any process and see what it contains, how it is designed, and what elements are available. For our purposes we will be working with the Page() object most of the time, but any IE/FF browser window will require you to work with the process windows, buttons, and navigation elements which are all outside of the page object. Each object in a process is classified as a TestNode in TC. This means they all share certain basic properties, and a certain set of functions that you can call.
Now, open up Internet Explorer 7. You will see another node called Process("iexplore") appear. Click on the + and look at all the "Window" child nodes. These are all the child nodes contained within IE7. These include the navigation tabs, the popup windows, scrollbars, everything. The node labeled "Page" contains all the web page information.
Left click on the Page node once, and look through the items populated in the right frame. At the top will be the "path". This is the FullName field for the node. This is the absolute path to the element, and is unique. You can use this to uniquely identify any object, in any process, web page, frame, etc. However, every time the Node gets modified, this path will change. So while it provides us with an exact location of the element right now, it may not be an accurate location the next time the page loads. Now take a moment to look through the page properties and methods. In general most web page nodes will not have Fields or Events associated with them. You can use any properties to find a page object. This ends up being a much more accurate and long-lasting approach to finding web page elements.
In fact, if you click on the "Methods" tab of the Page node, you will see many different Find methods associated with any Test Node. Each one will require different paramaters, but any can be used to quickly find the element you are interested in interacting with.

Now look at the bottom of the frame on the right. There you will find helpful information, such as what parameters each Method takes. Look through the object browser, and familiarize yourself with the basic methods. Don't freak out if there is too much to handle. My next post will focus on making sense of the object browser, using the finder tool, and figuring out how to find the elements you need to work with.
First, open up TC7, and click on the "Object Browser" tab, in the upper left hand corner of TC. On the left, you will see a list of the currently running processes. On the right, a list of elements associated with the currently selected node. These elements include attributes, methods, events, and fields associated with the node.

By default all processes are shown, minus windows processes. If you want, you can choose to only display tested applications, or display windows processes as well. The object browser lets you see inside any process and see what it contains, how it is designed, and what elements are available. For our purposes we will be working with the Page() object most of the time, but any IE/FF browser window will require you to work with the process windows, buttons, and navigation elements which are all outside of the page object. Each object in a process is classified as a TestNode in TC. This means they all share certain basic properties, and a certain set of functions that you can call.
Now, open up Internet Explorer 7. You will see another node called Process("iexplore") appear. Click on the + and look at all the "Window" child nodes. These are all the child nodes contained within IE7. These include the navigation tabs, the popup windows, scrollbars, everything. The node labeled "Page" contains all the web page information.
Left click on the Page node once, and look through the items populated in the right frame. At the top will be the "path". This is the FullName field for the node. This is the absolute path to the element, and is unique. You can use this to uniquely identify any object, in any process, web page, frame, etc. However, every time the Node gets modified, this path will change. So while it provides us with an exact location of the element right now, it may not be an accurate location the next time the page loads. Now take a moment to look through the page properties and methods. In general most web page nodes will not have Fields or Events associated with them. You can use any properties to find a page object. This ends up being a much more accurate and long-lasting approach to finding web page elements.
In fact, if you click on the "Methods" tab of the Page node, you will see many different Find methods associated with any Test Node. Each one will require different paramaters, but any can be used to quickly find the element you are interested in interacting with.

Now look at the bottom of the frame on the right. There you will find helpful information, such as what parameters each Method takes. Look through the object browser, and familiarize yourself with the basic methods. Don't freak out if there is too much to handle. My next post will focus on making sense of the object browser, using the finder tool, and figuring out how to find the elements you need to work with.
Wednesday, September 16, 2009
Hi
Hello, this is my first blog post. This blog will focus on functionality for AutomatedQA's TestComplete. If you haven't used it before, you can download it at http://automatedqa.com.
This blog will focus on web-testing using TestComplete, and will contain strategies, problems, example functions, and cool solutions.
Stay tuned!
This blog will focus on web-testing using TestComplete, and will contain strategies, problems, example functions, and cool solutions.
Stay tuned!
Subscribe to:
Posts (Atom)